
Go Left To Read Older Entries
Michael Heilemann said it succinctly two years ago when he explained that pagination navigation should have newer stuff on the right, and older stuff on the left.
He wrote:
Consider a blog like a diary. You start writing on the first page and then go towards the right. And since the first page of a blog is the latest entry, to go to the older entries, you have to press the arrow that points to the left.
Left = Old.
He's got it right, and Wordpress (among others) has it wrong. I love Wordpress, and in order to help Wordpress users fix the code in their themes, here's some sample code that corrects Wordpress's default pagination navigation:
For pages with single entries:
<div class="left"><?php previous_post('« %','','yes') ?></div>
<div class="right"><?php next_post(' % »','','yes') ?></div>
And somewhat confusingly, for pages with multiple entries you should have the following:
<div class="left"><?php next_posts_link('previous', 0) ?></div>
<div class="right"><?php previous_posts_link(' newer', 0) ?></div>
This intuitive idiom is important enough to get right, despite the fact that Wordpress's backwards implementation has gained some traction.
My Movie Rating Service
The Setting
My wife would call me from the video store when the new DVDs came out and ask what we should watch. She'd already have grabbed a couple of DVDs with interesting covers, and would want to know if they were any good.
I'd hop online and see what the IMDB ratings were. But IMDB only showed one movie at a time, so we'd have to keep track of all the ratings in our heads as we mulled it over.
Worse, we wouldn't take advantage of the fact that I've got an account at Netflix, which has a very sophisticated algorithm to predict how much I'd enjoy a new movie based on the ratings I've given for other movies. It was too much trouble to navigate from the IMDB to Netflix, you see.
Worse still, we were only looking at the movies that the video store was showcasing. We weren't being made aware of movies that were generally thought to be better than the major releases, or movies that Netflix thought we'd love far more than the average viewer.
The Solution
I wrote a small web service, imdb.dlma.com, that does a few things:
- Display for each movie I asked: the IMDB rating, the Netflix average rating, and best of all, the personalized Netflix predicted rating.
- Remember the last few movies I asked about, and display them next to each other in a convenient table.
- Show me the best new releases of the week.
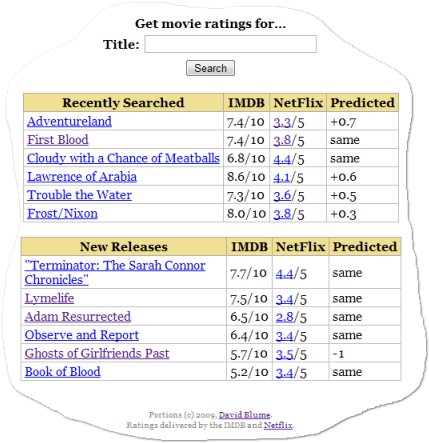
The service has been alive for a couple of weeks now, and it's paid off in spades! It's brought to our attention movies that we'd never heard of that we'd enjoy far more than the average person. And even more frequently, it's suggested to us that the movie we're thinking about renting won't be worth our time.
Thank you, little Movie Rating Service of mine!
Details
My website had a cron job that would scan all the weekly new releases from a Netflix feed, and of those, see which ones have 500 or more votes at the IMDB. (The first votes are generally skewed higher, because the first voters have a vested interest in the success of the movie.) Then it would get the average IMDB rating for the movie, the average Netflix rating for the movie, and then my predicted rating of that movie from the Netflix algorithm.
To do this, I had to use the official Netflix API, and grant permission, as a Netflix user, for my web service to request the predicted ratings for me. Yay, Netflix, for respecting my privacy, and for providing such an awesome API.
In addition to the cron job, the site allows me to enter the title of a movie, and it'll do its best to get the IMDB and Netflix ratings based on just that. If it can't tell exactly which movie I meant, it'll offer me a list of titles, and I'll select the one I meant.
Challenges
By far and away, the biggest challenge was that I was dealing with databases maintained by two different companies, with data entered inconsistently in both databases. It's very difficult to determine an exact match when dealing with such sets of data.
Consider that the IMBD associates movies with their original title in the original language. Thus, "The Good, the Bad, and the Ugly" is actually "Il buono, il brutto, il cattivo." And "Star Wars: Episode IV - A New Hope" is actually "Star Wars" at the IMDB. At Netflix, it's actually, "Star Wars: Episode IV: A New Hope," notice the colons instead of the hyphen.
The databases can get anything wrong: titles, names, year-of-release. For example, Adventureland: the IMDB has the year of release at 2009, but Netflix thinks it was released in 2008.
Further confounding the issue is that the databases contain TV series and video games, too. Consider that "Cloudy With A Chance of Meatballs" the movie and game are both released in the same year with the same title and have the same cast. How is an algorithm to determine which entry to use? (Hint: The ESRB rating values are thankfully different than the MPAA's.)
Sample Test Searches That Fail Without Fuzzy Matching
I wrote a "fuzzy match" algorithm that tries to accommodate as many near-misses between the databases as possible. The following list of titles illustrates some of the challenges that have cropped up.
| Pride and Prejudice | Sometimes written as "and" or &, sometimes HTML encoded. |
| Adventureland | Different years-of-release in the databases. |
| Dil Se.. | Ellipses at the end of one title, but not the other. |
| Rabu Hina | Quotation marks surrounding one of the titles but not the other. |
| The Good, the Bad and the Ugly | Title in Italian at IMDB, not at Netflix. |
| Run, Fatboy, Run | Commas at Netflix, "Fatboy" one word at IMDB. |
| Silent Light | "Stellet licht" at IMDB. |
| The Good | This is an exact hit. Algorithm should bypass choices. |
| Star Wars | Called, "Episode IV..." at Netflix with inconsistent subtitle separators. |
| First Blood | Called, "Rambo" at Netflix. |
| Cloudy with a Chance of Meatballs | Game and movie have identical details. |
 Entries
Entries