
My TechCrunch Feed Filter
It's the the sixth anniversary1 of my TechCrunch Feed Filter. In Internet time, that's ages. A lot has changed. Here's a look back.
The Problem
TechCrunch was a great blog about innovation and entrepreneurship. As it grew, it published more articles than I cared to read. Like many savvy blog readers, I used a feed reader to present the latest articles to me, but TechCrunch was simply too profuse.
The Solution
I created a service that'd visit TechCrunch's feed, and make note of who made which articles, what the articles were about, how many comments each article had, and how many Diggs2, Facebook likes and Facebook shares each article had.
With that data, the service would determine the median, mean, standard deviation, and create a minimum threshold for whether the article merited being seen by me. The raw data is stored in a live yaml file. There were some special rules, like, "If the article is by Michael Arrington, or has "google" in the tags field, automatically show it to me." Otherwise, other readers had to essentially vote the article high enough for it to pass the filter.
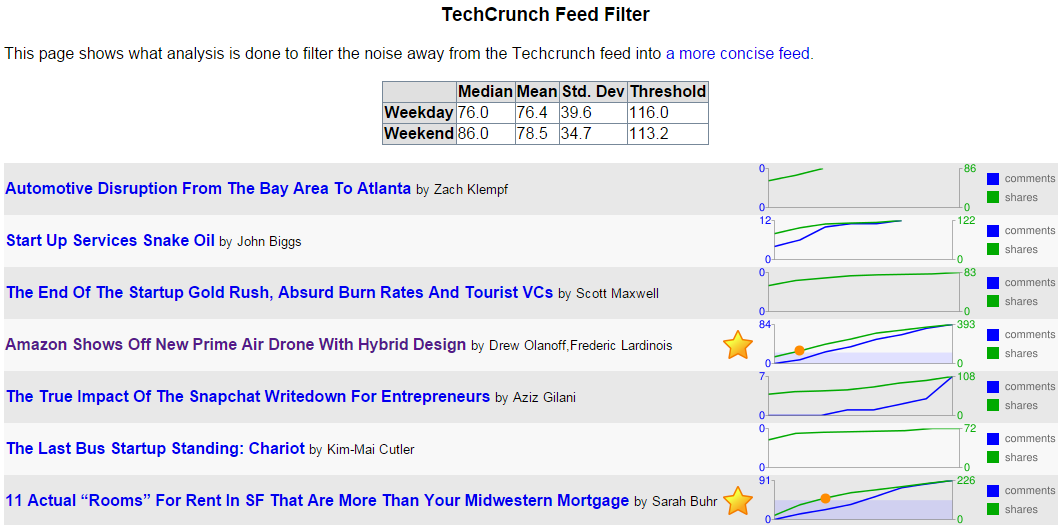
In the picture above, you can see that two posts out of seven met the criteria to be in the filtered feed. They're the ones with the gold stars. The threshold was calculated to be 116 shares, and you can see in the graph when each article had more than the threshold. (There's a red circle at the point the green shares line rose above the blue area that designates the criteria level.)
Once the service knew which posts were worthy of my attention, it listed them in its own filtered feed.
Changes over Time
In the beginning, TechCrunch used WordPress's commenting system. As such, its feed included the slash:comments tag. At the time, that was the best metric of how popular a TechCrunch post was, better than Facebook shares. But TechCrunch started experimenting with different commenting systems like Disqus and Facebook comments to combat comment spam. Neither of those systems used a standard mechanism to get comment counts, so every time it changed commenting systems, I had to change my service.
Digg, whose Diggs were once a great metric of the worthiness of a TechCrunch blog post, faded away. So I had to stop using Diggs.
So that left Facebook's metrics. They weren't ideal for assessing TechCrunch articles, but they were all that was left. Using Facebook likes and shared worked for a while. And then Facebook changed their APIs! They once had an API, FQL, that let you easily determine how many likes and shares an article had. The killed that API, leaving me with a slightly more complicated way to query the metrics I need for the service to do its work.
Not The End
I've had to continuously groom and maintain the feed filter over these past six years as websites rise, fade, and change their engines. And I'll have to keep doing so, for as long as I want my Feed Filter to work. But I don't mind. It's a labor of love, and it saves me time in the long run.
1 One of the original announcement posts.
2 Remember Digg? No? Young'un. I still use their Digg Reader.
Comments are closed.
 Entries
Entries