
Your Last Project before the Covid Shutdown

Remembering March 2020
The Covid-19 shutdown was four years ago, and everything just before seems like a blur. Do you remember what you were doing right before everything shut down? Would you want to look it up if you could? GitLab keeps a history of contributors' activities, and I looked up what I was doing.
I had created a simple project: a service that would text me when a website changed, watch-url.
So here's the thing: I'm fundamentally against having to make a service like that. I feel like any site that relies on something changing should have an RSS feed or a web service that clients can query. I try to make that clear in the Before You Start section of the README.md. So my making this thing was under protest.
Salesforce Tower Tours
At the time, Salesforce Tower in San Francisco was occasionally offering tours to the top. To get on a tour you signed up at a site, salesforcetowertours.com, when they had openings. Problem was there was no telling when they'd update the page to allow sign-ups. Anytime they opened the site for reservations, it'd fill up in minutes, and the page would revert to the "Please come back later" page.
It was practically impossible to get reservations. My wife had been trying for weeks, and was on their email list, but it wasn't getting the job done. Their site didn't have an RSS feed or a web API. So I wrote that little web service so my wife could learn when reservations were available again. It was all for Salesforce Tower tours!
Then the U.S. shut down for Covid in March 2020, and there were no more tours to the top of Salesforce Tower. There was no more point to my little script. Oh, well.
Nudging a favorite site to get RSS
Since I decided to open-source watch-url, I chose a better example site to watch in the README, not the Salesforce site. I chose Nicky Case's ncase.me, because her site is amazing, everybody should visit it, and it tragically didn't have RSS, so some fans wouldn't know if/when she posted something new. So I used it in the README example setup:
./watch_url.py https://ncase.me/
It was my way of saying that I loved her site, and I wished there were a better way to get notified whenever she updates it. (Since you can't always trust email, as Cory Doctorow pointed out when 2600's HOPE email got filtered away by Google.)
Later On, an Unexpected Win
So here I am in January 2024, reminiscing about February 2020, and bemoaning that we may never get on a tour to Salesforce Tower.
But guess what? Nicky Case added RSS to her site! I subscribed! And now I get notifications for her new posts. That's a win!
Photo by Bru-nO / Pixabay Content License
Still not Defeated

Every few years, disparate web services seem to conspire to shutdown or break at the same time. It happened again last month. Some of them you may have heard of, but the others broke or disappeared without any prior announcement. I've been through this sort of thing before, so I knew it'd eventually take a little work to keep my services humming along again.
Google Plus
Google Plus announced that they'd shut down their service ten months before doing so. That gave me a few months to avoid addressing the issue, and then eventually getting around to backup up my posts. I love my backup, it's so much faster to load and navigate than Google's service.
Google Image Charts
Google Image Charts gave us seven years to prepare for their shutdown. They even staged one short and one long outage to draw our attention to the upcoming closure. I ignored it the whole time, and then scrambled to find a replacement after the permanent closure.
FourSquare Activity Feeds
FourSquare shut down their user activity feeds without any notice. They were in a sort of limbo as they tracked Swarm activity, but the URLs were still FourSquare. The feed was very important to me because I maintain a lifestream. I became a FourSquare developer to access my content, and discovered that I could make a more informative feed on my own than the feed they'd just killed. Yay! That turned out to be an unexpected win.
Internal Server Errors
My shared web hosting service started suffering intermittent "internal server errors" (HTTP code 500) at the same time as the above changes. I turned off FastCGI, but that didn't help. Then I upgraded PHP from 5.6 to 7.2, which broke my blog engine (Habari), so I fixed that, but the "500"s kept happening. As a last resort, DreamHost moved my site from Virginia to some new servers in Oregon. That fixed the issue, and even better, upgraded my account to a Linux distro that uses Python 3.6! Yay, that means I finally get to use f-strings at DreamHost! DreamHost was the last place where I couldn't use f-strings, so I'm really happy that they've caught up.
Despite the handful of shutdowns and failures, I ended up with a couple of unexpected wins over the previous situation, so I'm pretty happy about that.
Photo by Andrew Wallace / CC BY-NC-ND 2.0
Father's Day Challenge

Here's a puzzle my son put in my Father's Day card. He wrote, "In the figure below, fill in each of the sixteen numbers from 1 to 16 such that the four rows and three columns (use the lines as a guide) add up to 29."
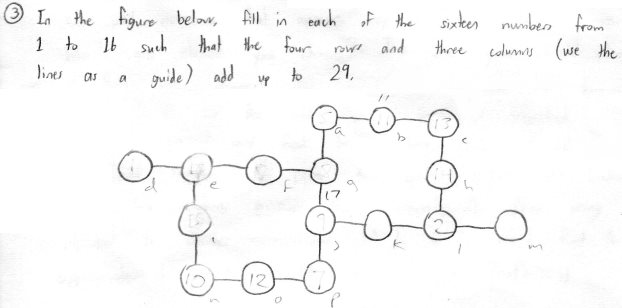
You can tell from the pencil markings that I tried to solve it by hand. But it wasn't long before I thought about trying to solve it with a Python script. There's a naïve script that you could write:
for permutation in itertools.permutations(range(1, 17)):
if rows_and_cols_add_up(permutation):
print permutation
That one just tries every single ordering of the numbers and then presumably checks things like sum(p[0], p[1], p[2]) == 29 in the testing function. The only problem with that approach is that the potato I'm using for a computer might not finish going through the permutations before the next Father's Day. (No, really. There are over 20 trillion permutations to check.)
Fast but Not Exactly Correct
So I decided to attack it from another angle, just look at the rows first. There are four rows, let's call them rows a, b, c, and d from top to bottom. Row a has a 3-tuple in it, b has a 4-tuple, c has a 4-tuple, and d has a 3-tuple. I wrote an algorithm that first finds all the 3-tuples and 4-tuples that add up to 29.
From those sets of valid 3-tuples and 4 tuples, the algorithm chooses a 3-tuple, a 4-tuple, another 4-tuple, and finally a 3-tuple. It assures that there are no duplicate numbers across any of the tuples. Then if that's true, it checks the three columns, and if they add up to 29, it prints the winning results.
And voilà, it worked, and demonstrated that there are multiple solutions, and found them in mere seconds! I saved that initial implementation as a gist. I thought I was done, but the code was bugging me. I knew that while it reflected the way I approached the problem, it was inefficient (it did too many comparisons), it included duplicate solutions (that's the "wrong" part of it), and it wasn't Pythonic.
Correct but Slower
So, a few hours later, I refactored the code, and realized I could replace four nested "for" loops (one for each row) with two loops that each choose two items from their containers (one container of 3-tuples, and one of 4-tuples). And I could check for no-duplicates on one line using a set() instead of explicitly checking for duplicates with "any(this in that)" calls.
The refactor replaced 22 lines of deeply nested code with four lines of simpler code. Not only were there fewer lines, I hoped the program became more efficient because it's iterating fewer times. That's the best kind of change! It's smaller, easier to reason about, and should be faster when executed. It's very satisfying to commit a change like that! The changes to the gist can be seen here:

The red lines are being replaced by the green lines. It's nice to see lots of code being replace by fewer lines of code.
Correct and Fast
I was wrong about it being faster!
Profiling showed that while the change above was more correct because it didn't include duplicate results, it was inefficient because it lacked the earlier pruning between the for loops from the first try. Once I restored an "if" call between the two new for loops, the program became faster than the first run.
for b, c in itertools.combinations(t4, 2):
if len(set(b + c)) == 8:
for a, d in itertools.combinations(t3, 2):
if len(set(a + b + c + d)) == 14:
test_rows(a, b, c, d)
It's very rewarding to bend your way of thinking to different types of solutions and to be able to verify those results. This feeling is one of the reasons I still code.
Here's the final version of the solution generating code.
Photo by William Doyle / CC BY-ND 2.0
My TechCrunch Feed Filter
It's the the sixth anniversary1 of my TechCrunch Feed Filter. In Internet time, that's ages. A lot has changed. Here's a look back.
The Problem
TechCrunch was a great blog about innovation and entrepreneurship. As it grew, it published more articles than I cared to read. Like many savvy blog readers, I used a feed reader to present the latest articles to me, but TechCrunch was simply too profuse.
The Solution
I created a service that'd visit TechCrunch's feed, and make note of who made which articles, what the articles were about, how many comments each article had, and how many Diggs2, Facebook likes and Facebook shares each article had.
With that data, the service would determine the median, mean, standard deviation, and create a minimum threshold for whether the article merited being seen by me. The raw data is stored in a live yaml file. There were some special rules, like, "If the article is by Michael Arrington, or has "google" in the tags field, automatically show it to me." Otherwise, other readers had to essentially vote the article high enough for it to pass the filter.
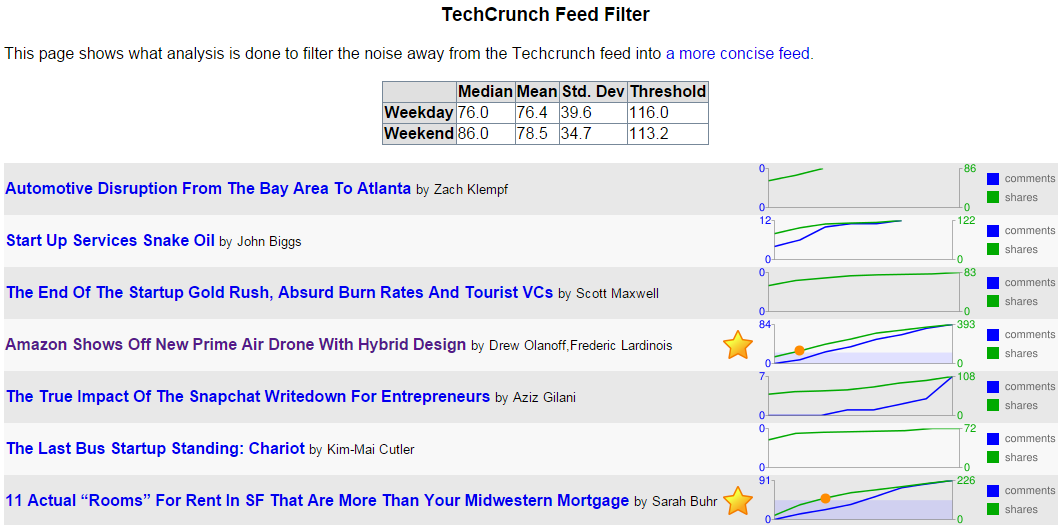
In the picture above, you can see that two posts out of seven met the criteria to be in the filtered feed. They're the ones with the gold stars. The threshold was calculated to be 116 shares, and you can see in the graph when each article had more than the threshold. (There's a red circle at the point the green shares line rose above the blue area that designates the criteria level.)
Once the service knew which posts were worthy of my attention, it listed them in its own filtered feed.
Changes over Time
In the beginning, TechCrunch used WordPress's commenting system. As such, its feed included the slash:comments tag. At the time, that was the best metric of how popular a TechCrunch post was, better than Facebook shares. But TechCrunch started experimenting with different commenting systems like Disqus and Facebook comments to combat comment spam. Neither of those systems used a standard mechanism to get comment counts, so every time it changed commenting systems, I had to change my service.
Digg, whose Diggs were once a great metric of the worthiness of a TechCrunch blog post, faded away. So I had to stop using Diggs.
So that left Facebook's metrics. They weren't ideal for assessing TechCrunch articles, but they were all that was left. Using Facebook likes and shared worked for a while. And then Facebook changed their APIs! They once had an API, FQL, that let you easily determine how many likes and shares an article had. The killed that API, leaving me with a slightly more complicated way to query the metrics I need for the service to do its work.
Not The End
I've had to continuously groom and maintain the feed filter over these past six years as websites rise, fade, and change their engines. And I'll have to keep doing so, for as long as I want my Feed Filter to work. But I don't mind. It's a labor of love, and it saves me time in the long run.
1 One of the original announcement posts.
2 Remember Digg? No? Young'un. I still use their Digg Reader.
Ways to Break a Dollar into Change

I'm going to retire a technical interview question that I've had ready to ask, but turns out to probably be too difficult. It's more a wizard-level interview question, or a casual technical discussion with peers who don't feel like they're under the gun.
How many ways are there to break a U.S. dollar into coins?
It seemed appropriate to ask this to some candidates, because once you know what you're trying to do, the algorithm in Python naturally reduces down to five or six lines of code.
def ways_to_break(amount, coins):
this_coin = coins.pop(0)
# If that was the last coin, only one way to break it.
if not coins:
return 1
# Sum the ways to break with the smaller coins.
return sum([ways_to_break(amount - v, coins[:])
for v in range(0, amount+1, this_coin)])
print ways_to_break(100, [100, 50, 25, 10, 5, 1])
You could click on the gist with more comments and better variable names if you want to try to better understand that. It's not meant to be production code, it's a whiteboard snippet made runnable.
Here's what I hoped to look for, from the candidate: After maybe clarifying what I wanted, ("what about the silver dollar or half-dollar coins? Did you want permutations or combinations?"), the problem should seem well-defined, but hard. Then, I'd hope the candidate would break it down to the most trivial cases: "How many ways are there to break 5¢ if you have pennies and nickels? How about 10¢ with pennies, nickels and dimes?" Can these trivial cases be used to compose the bigger problem?
At that point, different areas of expertise would appear. Googlers might start jumping towards MapReduce, and already figure that Reduce is simply the summation function because the question is "how many", and have the thing worked out at scale.
Imperative programmers, having thought about the simplest cases, probably clue in that there's an iterative approach and a recursive approach.
Pythonistas who prefer functional programming probably have reduce(lambda x, y: x+y [x, y in ...]) ready to go.
That got me thinking. I didn't see the need for reduce and operator.add and enum. My solution above isn't above criticism, but I think it's easier to read than some of the alternatives. In truth, it really depends on who that reader is, and how their experience has conditioned them.
While writing the algorithm, I searched the question online, and was pleasantly surprised to see Raymond Hettinger mentioned for solving the puzzle. He's a distinguished Python core developer. Too bad he probably didn't have Python then, in 2001, to help him solve the problem in a scant few lines.
Taking it up a Notch
Adam Nevraumont proposed the following challenge:
Drop the penny, and try to break $1.01. The Canadian penny has been retired, after all.
He provided the answer: Check that the remaining coin can break the amount. Don't assume it can. This also relieves the restriction that the container of denominations be ordered!
def ways_to_break(amount, coins):
this_coin = coins.pop()
# If that was the only coin, can it can break amount?
if not coins:
if amount % this_coin:
return 0
else:
return 1
# Sum the ways to break with the other coins.
return sum([ways_to_break(amount - v, coins[:])
for v in range(0, amount+1, this_coin)])
print ways_to_break(100, [1, 100, 10, 50, 25, 5])
(It's actually more efficient to pop the largest denominations first. But I wanted to show that you can use an unordered container now.)
Photo by Ian Britton / CC BY-NC 2.0
 Entries
Entries