
My Movie Rating Service
The Setting
My wife would call me from the video store when the new DVDs came out and ask what we should watch. She'd already have grabbed a couple of DVDs with interesting covers, and would want to know if they were any good.
I'd hop online and see what the IMDB ratings were. But IMDB only showed one movie at a time, so we'd have to keep track of all the ratings in our heads as we mulled it over.
Worse, we wouldn't take advantage of the fact that I've got an account at Netflix, which has a very sophisticated algorithm to predict how much I'd enjoy a new movie based on the ratings I've given for other movies. It was too much trouble to navigate from the IMDB to Netflix, you see.
Worse still, we were only looking at the movies that the video store was showcasing. We weren't being made aware of movies that were generally thought to be better than the major releases, or movies that Netflix thought we'd love far more than the average viewer.
The Solution
I wrote a small web service, imdb.dlma.com, that does a few things:
- Display for each movie I asked: the IMDB rating, the Netflix average rating, and best of all, the personalized Netflix predicted rating.
- Remember the last few movies I asked about, and display them next to each other in a convenient table.
- Show me the best new releases of the week.
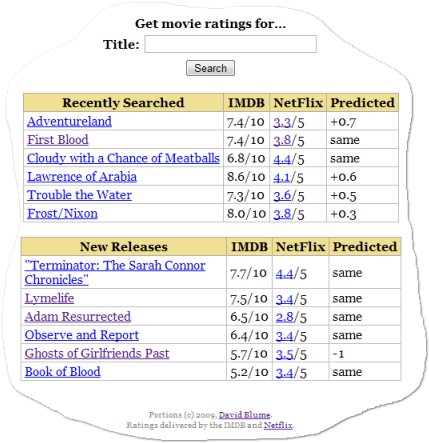
The service has been alive for a couple of weeks now, and it's paid off in spades! It's brought to our attention movies that we'd never heard of that we'd enjoy far more than the average person. And even more frequently, it's suggested to us that the movie we're thinking about renting won't be worth our time.
Thank you, little Movie Rating Service of mine!
Details
My website had a cron job that would scan all the weekly new releases from a Netflix feed, and of those, see which ones have 500 or more votes at the IMDB. (The first votes are generally skewed higher, because the first voters have a vested interest in the success of the movie.) Then it would get the average IMDB rating for the movie, the average Netflix rating for the movie, and then my predicted rating of that movie from the Netflix algorithm.
To do this, I had to use the official Netflix API, and grant permission, as a Netflix user, for my web service to request the predicted ratings for me. Yay, Netflix, for respecting my privacy, and for providing such an awesome API.
In addition to the cron job, the site allows me to enter the title of a movie, and it'll do its best to get the IMDB and Netflix ratings based on just that. If it can't tell exactly which movie I meant, it'll offer me a list of titles, and I'll select the one I meant.
Challenges
By far and away, the biggest challenge was that I was dealing with databases maintained by two different companies, with data entered inconsistently in both databases. It's very difficult to determine an exact match when dealing with such sets of data.
Consider that the IMBD associates movies with their original title in the original language. Thus, "The Good, the Bad, and the Ugly" is actually "Il buono, il brutto, il cattivo." And "Star Wars: Episode IV - A New Hope" is actually "Star Wars" at the IMDB. At Netflix, it's actually, "Star Wars: Episode IV: A New Hope," notice the colons instead of the hyphen.
The databases can get anything wrong: titles, names, year-of-release. For example, Adventureland: the IMDB has the year of release at 2009, but Netflix thinks it was released in 2008.
Further confounding the issue is that the databases contain TV series and video games, too. Consider that "Cloudy With A Chance of Meatballs" the movie and game are both released in the same year with the same title and have the same cast. How is an algorithm to determine which entry to use? (Hint: The ESRB rating values are thankfully different than the MPAA's.)
Sample Test Searches That Fail Without Fuzzy Matching
I wrote a "fuzzy match" algorithm that tries to accommodate as many near-misses between the databases as possible. The following list of titles illustrates some of the challenges that have cropped up.
| Pride and Prejudice | Sometimes written as "and" or &, sometimes HTML encoded. |
| Adventureland | Different years-of-release in the databases. |
| Dil Se.. | Ellipses at the end of one title, but not the other. |
| Rabu Hina | Quotation marks surrounding one of the titles but not the other. |
| The Good, the Bad and the Ugly | Title in Italian at IMDB, not at Netflix. |
| Run, Fatboy, Run | Commas at Netflix, "Fatboy" one word at IMDB. |
| Silent Light | "Stellet licht" at IMDB. |
| The Good | This is an exact hit. Algorithm should bypass choices. |
| Star Wars | Called, "Episode IV..." at Netflix with inconsistent subtitle separators. |
| First Blood | Called, "Rambo" at Netflix. |
| Cloudy with a Chance of Meatballs | Game and movie have identical details. |
About My Lifestream
I'm really proud of my lifestream. Originally I got the idea from Jeremy Keith. (And I use a subset of his style. I intended to use my own style, but I simply love his, and I don't have any design skill.) A lifestream is an aggregation of your user activity feeds from across the internet. Essentially, it can be thought of as an automatic online diary. It writes itself.

I think I can be thought of as a late early-adapter. I thought I had a lot of original ideas as I made my lifestream, but it turns out that more often than not, somebody else had already implemented one of the ideas. Happily, no one seems to have made all the same decisions as me, so my effort wasn't wasted. For me, my lifestream really is the best lifestream ever! Here's why:
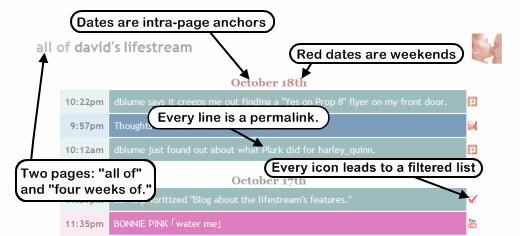
The Best of Both Worlds
Jeremy implements his as an aggregation of RSS and Atom feeds with no persistent storage of previous entries. So, as newer entries are made, the oldest entries are lost forever. His lifestream is always only the most recent few entries. Jeff, on the other hand, implements his with APIs, so he has access to the complete history of entries for any account. I maintain mine with feeds, but I imported my entire history from many accounts. My lifestream is huge, and spans years, even though I just started it a couple of months ago.
Also The Best of Both Worlds
Jeremy's lifestream is handy, because it never becomes unwieldy. It'll always be about the same size. Jeff Croft's and Emily Chang's persist every entry and thus continuously grow. They paginate their lifestream. You can view page 234 out of 399, for example.
I decided that 98% of the time, I'm only interested in something I wrote down in recent memory. Say, the last four weeks. So I made that the index page of my lifestream. Just the 28 most recent days of my online activity. It make for a nice, small page.
But the other 2% of the time, I'm searching for something older, or I'm feeling nostalgic. So I put my entire lifestream on one page, too. Sure, it's big, and I'll never browse it from a phone, but modern web browsers are perfectly capable of downloading it and rendering it, and will be able to do so for years to come. The entire history really has the same appeal to me as being able to search through a diary.
Even if I decide to paginate it eventually, it'll be easy, the backend will facilitate that.
The Details Matter
Since I provide my entire lifestream on one page, I also made sure to include the year for dates that precede this year. (Eg., October 5th, 2006. Note that that uses the intra-page anchor, another important detail.)
My lifestream has a discoverable RSS feed too.

But you know what? Nobody'd want a feed of a lifestream that constantly updates for individual entries. That's one thing that really bothers me about sweetcron feeds. They're just too noisy. Update, update, update!
So the RSS feed for my lifestream only provides weekly updates. That's what I'd really want from a lifestream feed. Just some sort of nice regular overview of all the activity over a certain period of time. And its permalinks are intra-page links into the huge complete history page.
Some of the accounts that I include in my lifestream don't support user activity feeds. For example, YouTube's feed for each user's Favorited videos doesn't have "date-favorited" information associated with it. Since I wrote my own lifestream engine, I was able to work around that problem. I doubt that most lifestream services like FriendFeed would go to the lengths I did in ensuring that I get exactly the information I want, regardless of whether or not the site's feed or API supports it.
It Helps Me Find Things
Searching for things half-remembered turns out to be pretty successful at the lifestream. I sometimes don't know if I posted a link to delicious, or if I plurked it.
It Encourages Me To Write More Clearly
I always think twice before I write a clever title to a tweet, plurk, or blog entry. I realize now that I may well be searching for that entry in the lifestream later, and the lifestream may only have the title. (The lifestream also contains actual content from the entries, but the content isn't presented in the web pages. So maybe the content will be searchable too, eventually.)
Cleverness is out. Accessibility and searchability are in when you have a persistant searchable lifestream. Now, I strive for clarity in my titles.
I also stopped services that cross-post from one service to another. Having the lifestream made the idea of cross-posting even more redundant. If my livejournal friends don't want to see my tweets, I won't force them to with LoudTwitter.
 Entries
Entries