
My Location Predictor
I made a web page that predicts where I'm going. It was a fun little academic exercise, and I thought some of the challenges were interesting.
Ever since it came out that Apple was tracking and keeping location data on everyone's iPhones, and owners could get to that data my curiosity was piqued. Apple was quick to stop tracking so much data and to limit access to the database, but I saved off my phone's database of locations while I could. Later, I installed a new app, OpenPaths, that intentionally and continuously logs my phone's locations and makes that data available to me.
Now that I was logging my phone's locations in the background, I could ask myself what I wanted to do with the data. I knew what I wanted to do right away! I wanted the computer to answer the following question:
Given where I've been, where am I probably going now?
I'd make a webpage whose only job it was to display its answer to that question. It's a simple web page to look at, but the devil's in the details.
Sensible Predicting
The human brain is wonderfully better at answering that sort of question than the computer. It's a matter of pattern recognition across at least three dimesions: time and two-dimensional space.
I started with the way I'd think about answering that question:
If there aren't any notable exceptions, like travelling for work or vacation, then I follow a bi-weekly schedule more closely than a weekly schedule. So I'd look at where I was at this time of day two weeks ago.
To translate that into an algorithm for the webpage a few things need to happen. I have to codify what a "notable exception" is. Perhaps it's being more than 100 miles away from home for more than a day or two. Or, if I'm currently away on vacation, then the program shouldn't be looking at what I've been doing two weeks ago at home.
Here's the algorithm that the computer uses:
- If I was near here two weeks ago, consider where I was going back then at this time.
- Otherwise, consider where I was at this day of the week last week.
- If I was away on each of those occasions, then how about where I was yesterday at this time?
Simple enough. But the question of "two weeks ago at this time of day" itself is a bit ambiguous. Two things get in the way of that that the human brain just automatically figures out. One, time-of-day is local. If I am in California today, but I was in Hawaii two weeks ago, I can pretty easily calculate "breakfast time" for either. But the computer would have to first translate latitude and longitude coordinates into time-zones on the Earth. Then it'd be able to calculate relative time-of-day for either week at either location. The other issue, daylight savings time throws off the way a program might naïvely calculate "two weeks ago."
Account for daylight savings time
"Two weeks ago at this time of day" is a loaded phrase. The naïve approach for a computer that keeps track of time by incrementing seconds would be to subtract the number of seconds in a day, and do that 14 times. But that doesn't account for daylight savings time, which would throw off the results for 4 weeks out of a year.
My program uses Python, which has a library to translate time from epoch timestamps (which are used by OpenPath's library) to a calendar date and time-of-day format that's more native to the human mind. So the actual code calculates "number-of-seconds to this time-of-date two weeks ago" as follows:
now - time.mktime((datetime.fromtimestamp(now) -
timedelta(days=14, hours=0)).timetuple())
Huh, that's sort of wordy compared to the naïve alternative, but the important thing is that this approach is always correct. Once we've figured out when "two weeks ago" actually is, then we can calculate what "where" and "how far" actually mean...
Distance Calculations
If you're near the equator, then calculating short distances using latitude and longitude can be approximated by an equation based on Pythagorean Theorem. What's funny is that if you search the web looking for the algorithm in Python, you'll usually see something like the following function:
def distance(p1, p2):
return math.sqrt((p1[0] - p2[0])**2 + (p1[1] - p2[1])**2)
But as long as you're importing the math module anyway, it'd be even more direct if you just used math's own "hypot" (short for "hypotenuse") function:
def distance(p1, p2):
return math.hypot(p1[0] - p2[0], p1[1] - p2[1])
But that calculates planar distance, and we're not on a plane. We're essentially on a sphere. So it's better to use the Haversine formula if we want to get an accurate distance between two points defined by latitude/longitude coordinates.
Now that timedelta and the Haversine formula handle the "when" and "where" in my fuzzy algorithm, it's time to take a look at the presentation of the data.
The Webpage Itself
So much for the algorithm. What about the quality of the webpage itself?
Responsive Webpages
It's a small webpage. So it's only sensible and intuitive that it'd be a quick and responsive webpage, too. But the webpage wouldn't work without making relatively long queries to two remote services.
- Retrieve new location data from the remote OpenPaths API service.
- Retrieve specific map data from the Google Maps API service.
In between the two big remote queries, the program needs to perform the actual prediction for where I'm going to be based on the OpenPaths data, and send the predicted points to Google Maps. There's no way to avoid the fact that the webpage is going to take a few seconds to do all its work.
The best work-around for that is two things:
- Ajax. The web server can quickly serve a simple HTML web page to the client which'll get displayed for the user right away. Then the browser can make another request to the server for just the data that takes a long time to calculate and retrieve.
- Caching. Once I've retrieved raw datapoints and made the prediction calculations, then that prediction shouldn't change for a few minutes. I can save off my prediction and immediately hand it back the next time the webpage is requested, if it's requested relatively soon.
Well-behaved Webpages
It's critical to me that the webpage be small and simple. It has to get to the point as quickly as possible. But it's also important to me that I give credit to the tools and services I used to make it possible. That called for some credits to be put in a footer.
I wanted the footer to be relative to the browser's window viewing the page. But if that window was too short, then the footer would end up overwriting or being overwritten by the map or the text above the map. The fix for that was some clever CSS that put the footer at the bottom of the window, but never let it cover up the important part of the page, the map.
So far so good. But then I discovered something unexpected...
Bad Data
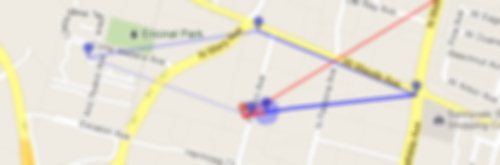
Sadly OpenPaths seems to collect bad data from my phone occasionally while it's at rest. All of the recorded and predicted movement in the map below is due to bogus data from OpenPaths.
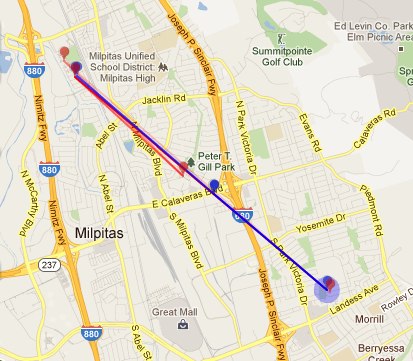
All of the points along the same angle that extends to the south east are bad data. The phone didn't go anywhere all that time. I have no idea why it sometimes pretends to travel to that part of town, but I don't like it. This called for another interesting algorithm that's better suited for a human brain:
If the datapoints smell fishy, don't use them.
It's really easy for me to detect which datapoints are bad, and not only just because I know where my phone's been. It's because there's a certain pattern, the angle and distance traveled by the bogus points. So I've got a work-in-progress algorithm the elides points that smell fishy.
A Secret Mode
The main point to the site was the prediction. But as long as I had all this historical data, it seemed like a shame if I couldn't easily look it up, too. So there's a secret mode, impossible to find and discover. (Since nowadays people don't read long blogs or actually type in the URL bar of their browsers.)
If you add an HTTP "GET" parameter, t, to the URL, the website will return a corresponding location history instead of a prediction of where it thinks I'm going to be. t can take one of three different forms, a UNIX timestamp, an RFC 2822 date and time, or a negative number of days to look back. Here are some examples:
https://david.dlma.com/location/?t=1279684897
I flew in to Los Angeles on that day. Timestamps are good if you're already dealing with them or want a relatively short token to represent an absolute time. Otherwise, they're an epoch fail waiting to happen.
https://david.dlma.com/location/?t=2012-02-20T13:30:00
Took the kids to Disneyland that day. Fun! That date format is handy if you want to browse my location history and are thinking in terms of calendar dates.
https://david.dlma.com/location/?t=-7
What'd I do last week? This is handy if I don't need an absolute time and date, but just want an offset from the current time and date.
Finally, I've got a micro site that was really fun to build and with which I'm quite pleased.
My Dead Man's Switch

I wrote a dead man's switch to update some of my online accounts after I die.
What It Is
The basic idea is that if I pass away unexpectedly, I'd want my online friends to know, rather than for my accounts to go silent without any explanation at all. I wrote a program to take notice of whether or not I seem to still be alive, and once it's determined that I've died, it'll follow instructions that I've left in place for it. It'll do this over the course of a few days. Well, I won't tell you when it'll stop, that'd be taking some of the surprise out of it.
Two things caused me to do this. First, I wrote a lifestream. Essentially, I already wrote a computer program (a cron job, technically) that takes note of nearly everything I do online already. It was a handy thing to have, and it seemed like it could do just a little bit more with hardly any effort.
Second, I read the books Daemon and Freedom™. A character in those books also wrote a program (a daemon in his case) to watch over its creator's life, and then to take certain actions upon its creator's death. The idea got under my skin, and I just had to write a similar program of my own.
How It Works
This section will get technical, but it'll be of interest for those who also want to write their own.
Everything is in Python. The lifestream I have uses feedparser to read in and process each of the feeds affected by my online activity (sometimes called user "activity feeds"). It stores certain information in a yaml file. Here's an excerpt from the file itself.
-
etag : 2KJcCROqtyI4nqaQEg34109rfx4
feed : "http://my.dlma.com/feed/"
latest_entry : 1326088652
modified : 1326090583.0
name : mydlma
style : journal
url : "http://my.dlma.com"
The most relevant item in the file is that there's a field called, "latest_entry", and the data for that field is a timestamp. The latest "latest_entry" would then be the most recent time I've been observed doing anything online.
Given that, all I had to do was write a new script that watched the latest "latest_entry", and when it became too long ago, it would assume that something bad had happened to me. (Which would be wrong, of course, if I was merely vacationing in Bora-Bora, and didn't have internet access for a couple of weeks.)
This new script would do something like the following:
- Continue to step 2 if David hasn't done anything online for a few days. Otherwise keep waiting.
- Decide which posts to make at which times, and make note that those posts themselves don't now make it look like David's still alive and that the switch should deactivate.
Once the script thinks I've been offline for too long, it writes a cookie to file, and then goes from watching mode to posting mode.
In posting mode, the script looks over its entire payload of messages to deploy. I used the filesystem to maintain the payload, much like dokuwiki does. (Others might think that a database would be preferable. Sure, that'd be fine, too.) My payload files encode data into the filename, too. The filename is composed like so: [delay_to_post]-[service_to_post_to]-[extra_info].txt. That way, when I display a listing of the directory, I can see an ordered list of which messages go when.
Message Delivery
Messages that go to blogging services like WordPress or Habari use the AtomPub API. Messages that go to other services generally use OAuth 2.0 for authentication, then use a custom API to deliver the message.
Once a message has been successfully delivered to its service, it gets moved or renamed in such a way that it's no longer a candidate to get delivered again.
Development Process
The script runs as a cronjob, and usually just updates a status file. If it runs into a problem, it sends an email. (Fat lot of good that'll do if I'm already dead. But while I'm still alive, I'd like it to let me know if it's not happy.)
While I'm alive, I might still add posts to post later. When I add those new messages to post after my passing, I need to ensure that I didn't do anything wrong. (For example, the Habari payload is contained in an XML CDATA section, but the WordPress payload is plain XML, so I can't write any malformed messages.)
That's why as a part of routine maintenance, my dead man's switch also does payload data validation.
During script refactoring, I may want it to display certain diagnostic info directly to stdout. For that case, the script has optional debug, test, verbose and validate flags.
Risks
There's always the false positive, where it thinks I've died, but the rumour was greatly exaggerated. I'm actually looking forward to a few false positives, because they'll remind me that the dead man's switch is actually still running.
Another serious risk is that my dead man's switch relies on the successful continuous operation of my lifesteam script. There's an element to that lifestream script that degrades over time. Hopefully, I'll get around to mitigating that risk.
And yet another risk to my dead man's switch is continuously changing APIs. As I upgrade my Wordpress and Habari blogs, will they still accept AtomPub like they did when I wrote the switch in 2012? Will Twitter and Plurk still use the same OAuth protocol and API calls? Heck, will Dreamhost not upgrade Python to a version that's incompatible with my script?
Will I still have active accounts at the time of my passing? Will it then be illegal to continue to function online after you're dead? (Some bozo might die before me and do something stupid after he passes.)
There's a lot that could go wrong. But if these things don't go wrong, and my dead man's switch works correctly, that'd be pretty neat.
Have I got things to say to you!
Photo by matthileo / CC BY-NC-SA 2.0
Internet Security

Beware: I am a real neophyte when it comes to internet security. Having said that, I couldn't have fared any worse than Sony Pictures. They lost 1,000,000 plain-text passwords when a SQL injection vulnerability was discovered. I've been protecting against that attack since 2005. (At the part, "Is the password secure?" is where I say the passwords aren't stored in plain text. SQL injections have been the subject of security jokes for a long time, too. Ah, Little Bobby Tables.)
There have been and continue to be large breaches of personal data on the internet. Nathan Yau shares an infographic of the largest data breaches of all time.
My immediate family and I need a way to keep each other up to date with our changed account info and ID numbers. We need a solution that meets the following usability criteria:
- Accessible anywhere, from any device. It has to be practically just one click away.
- Trivial, memorable URL. We may be typing it directly into the URL bar.
- Always up-to-date. Any change made from anywhere is accessible immediately from any other client.
If it's not that easy to use, it won't be used, and there'd be no point in making it. On the other hand, it has to have the following security criteria:
- Accessible anywhere, from any device. It has to be secure even over a public wifi network.
- Secure from remote client attacks. It has to handle attacks over the internet.
- Secure from local attacks. It has protect against disgruntled hosting company employees.
With all that in mind, I've decided to roll my own information vault. Here are some goals and notes from that venture:
Be A Low Value Target
My first line of defense is that my information vault is just for me and my family. This'll never store enough data of real value to make it a target for the economics of it. I might get attacked, but it'd only be for the idle challenge of it.
Block Direct Access of Data Files
Move data files off the server, even though they're encrypted, or into directories tightly controlled by permission settings and .htaccess instructions. Test both attacks. If your encrypted files can fall into your attacker's hands, they can try a local brute force attack. (More on that below.)
Use HTTP Secure
For any data that is accessible, use HTTPS. This is the first line of defense if you want your data accessible over a public wifi network.
Unique and Long Master Password
Force your users to use a long random, impossible-to-guess master password. Prevent any sort of social attack: No names, dates, or places. In my case, since I'm the creator of the tool, I can do this.
Use a Hard-To-Compute Hash for the Master Password
Related: Do not store the master password anywhere. And the salted hash you use for it should be secure. Refer to this wikipedia article on cryptographic hash functions to see relative weaknesses of the functions. I've considered throwing in with a hashing algorithm that adapts to faster hardware to frustrate brute-force attacks.
Don't Store any Data in Plain Text
This is a defense against a local attack from someone who can obtain file-level access, like a company employee with admin access.
Sony Pictures stored private data in plain text format, and thus enabled this interesting analysis of passwords in the Sony Pictures security breach. Consider your encryption algorithm carefully. I used AES, but am keeping my options open. I can change my backend at any time.
Limit Cookie Scope
Limit your HTTPS cookie scope with morsels like max-age, httponly, domain, path and secure morsels.
While you're at it, it doesn't hurt to salt cookie and session data with an identifier associated with the request. In Python you could use os.environ['REMOTE_ADDR'].
Protect Against Javascript / SQL Injection
Know what kinds of attacks can be performed. Encode characters that have special meaning for the languages you use, like the quotes characters, <, >, and &, among others. In Python, the bare minimum you'd use is cgi.escape for that, but you'd want to use other functions depending on where/how the data is travelling or being displayed.
Analyze and Act Upon Suspicious Activity
It's not enough that your server is passively logging each access. Your site needs to analyze recent activity and take action (like email you or ban certain origins) when preset triggers are tripped.
Keep Protecting
Security is not a product, but a process." --Bruce Schneier, author of "Applied Cryptography"
This blog entry may have already has fallen out-of-date with new measures I've taken to protect our information vault.
If I'm missing a vector of attack, or you have some practical advice for me, I'd appreciate hearing from you.
Prettiest Little QR Code Ever
This is the chronicle of a misguided attempt to create a small, aesthetically pleasing QR Code.
The premise was absurd. The smallest QR Codes are 21 dots across. That's not enough room for any signifcant art, much less aesthetic beauty. Even worse is the fact that QR Codes compress information and support error correction. Well, that's great for the code, but bad news for the aesthetic.
Successful compression guarantees uniform density of information. There's visual noise everywhere. Art requires something else: sparcity, shape or symmetry. Beauty requires something to bring it out.
So, I was starting with guaranteed uniform noise, and I wanted shape, symmetry and sparcity.
Yeah, this was going to work.
So, why did I even decide to try?
Well, I'm really proud of the QR Code for http://dlma.com/. Because the link is so short, the QR Code that represents it is the smallest possible type, at 21 dots across.

When I look at that image it's so obviously a combination of a dancing Rasta banana (dancing for tips in a hat), a jackhammer, and a Phoenix.

You see it? Of course you do.
If I could get the awesome banana-jackhammer-phoenix without even trying, I bet I could make a bee-yoo-tee-ful QR Code if I asked the computer nicely. Or made it work really hard at it.
I took a quick stab at every possible 21x21 QR Code that'd direct to my domain, but they all sucked. If I allowed myself to paint on a 25x25 canvas (the next size up for QR Codes), that'd give me a lot more breathing room.
So here's what I did: Starting at 0, or 0000000000, I had the computer count up in base 36 numbers to about zzzzzzzzzz. (Yep, "zzzzzzzzzz" is a number in base 36, it is over 3.5 quadrillion.)
For each and every number, I had the computer create many possible URLs that goes to dlma.com, and for each one of those URLs, I had the computer do every possible QR Code encoding at 25 dots across. (There are about three or four encodings at different levels of error correction.)
For example, for the base 36 number "52gb", there are 32 different URLs at the domain dlma.com, like so:
| URLs for 52gb | ||
|---|---|---|
| http://dlma.com/52gb | http://dlma.com/52gb/ | http://dlma.com/52g/b |
| http://dlma.com/52g/b/ | http://dlma.com/52/gb | http://dlma.com/52/gb/ |
| http://dlma.com/52/g/b | http://dlma.com/52/g/b/ | http://dlma.com/5/2gb |
| http://dlma.com/5/2gb/ | http://dlma.com/5/2g/b | http://dlma.com/5/2g/b/ |
| http://dlma.com/5/2/gb | http://dlma.com/5/2/gb/ | http://dlma.com/5/2/g/b |
| http://dlma.com/5/2/g/b/ | http://5.dlma.com/2gb | http://5.dlma.com/2gb/ |
| http://5.dlma.com/2g/b | http://5.dlma.com/2g/b/ | http://5.dlma.com/2/gb |
| http://5.dlma.com/2/gb/ | http://5.dlma.com/2/g/b | http://5.dlma.com/2/g/b/ |
| http://52.dlma.com/gb | http://52.dlma.com/gb/ | http://52.dlma.com/g/b |
| http://52.dlma.com/g/b/ | http://52g.dlma.com/b | http://52g.dlma.com/b/ |
| http://52gb.dlma.com | http://52gb.dlma.com/ |
If I were doing 5-digit numbers, then they'd generate 64 different URLs, and 6-digit numbers generate 128 different URLs. For each URL, the computer generated a few different QR Codes at different encoding rates, and for each of the QR Codes, they get rated for different visual attributes.
It can take nearly 10 seconds just to do 100 numbers. The program I used displayed 16 images at a time while it was doing the processing.

Mouse over the image to see categories.
Believe it or not, the codes above are the best of breed for certain categories of aesthetic of small QR Codes that lead to my domain. If you mouse over the image, a legend will appear that says to which category each one of those codes belongs. "Darkest" means "has the most black dots" and "lightest" means the opposite. "Least lines" could also be called, "has the most individual dots, making checkerboard patterns." So "most lines" would mean has the least individual dots, making it the "clumpiest" code of them all. Technically speaking, that is.
The program that did the analysis has a lot of great features. It was all written in Python, except for the QR Code generator, which is a C++ Python module. The UI is one thread, while the worker thread is another. Every once in a while, the worker thread phones home to a remote web service and reports its results. That way, I could have multiple computers running the same analysis and they wouldn't step on each other. Each one also kept track of the best fifty codes for each category, giving me the chance to review 800 interesting QR Codes. I let computers run the program for days.
The result?
Well, let just say that there aren't many naturally beautiful QR Codes of size 25 or less. I ended up picking out three codes: One that sorta resembles an electrified soot sprite from Totoro from the heavy-center category, one that resembles Cthulhu from the H Symmetry category, and another that looks menacingly like Skeletor.
 Skeletor |  Soot Sprite |  Cthulhu |
All those hours of computing, and this was the best the program could come up with. No beautiful butterfly, eerily symmetric pattern, or falling rain of Matrix codes. Ah, well. At least I have a nice framework for whatever project I start next.
About My Lifestream
I'm really proud of my lifestream. Originally I got the idea from Jeremy Keith. (And I use a subset of his style. I intended to use my own style, but I simply love his, and I don't have any design skill.) A lifestream is an aggregation of your user activity feeds from across the internet. Essentially, it can be thought of as an automatic online diary. It writes itself.

I think I can be thought of as a late early-adapter. I thought I had a lot of original ideas as I made my lifestream, but it turns out that more often than not, somebody else had already implemented one of the ideas. Happily, no one seems to have made all the same decisions as me, so my effort wasn't wasted. For me, my lifestream really is the best lifestream ever! Here's why:
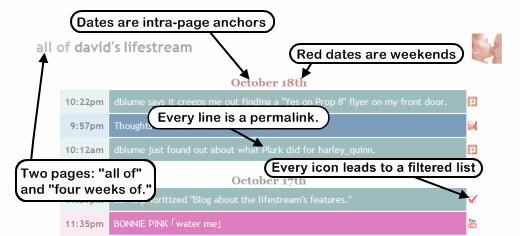
The Best of Both Worlds
Jeremy implements his as an aggregation of RSS and Atom feeds with no persistent storage of previous entries. So, as newer entries are made, the oldest entries are lost forever. His lifestream is always only the most recent few entries. Jeff, on the other hand, implements his with APIs, so he has access to the complete history of entries for any account. I maintain mine with feeds, but I imported my entire history from many accounts. My lifestream is huge, and spans years, even though I just started it a couple of months ago.
Also The Best of Both Worlds
Jeremy's lifestream is handy, because it never becomes unwieldy. It'll always be about the same size. Jeff Croft's and Emily Chang's persist every entry and thus continuously grow. They paginate their lifestream. You can view page 234 out of 399, for example.
I decided that 98% of the time, I'm only interested in something I wrote down in recent memory. Say, the last four weeks. So I made that the index page of my lifestream. Just the 28 most recent days of my online activity. It make for a nice, small page.
But the other 2% of the time, I'm searching for something older, or I'm feeling nostalgic. So I put my entire lifestream on one page, too. Sure, it's big, and I'll never browse it from a phone, but modern web browsers are perfectly capable of downloading it and rendering it, and will be able to do so for years to come. The entire history really has the same appeal to me as being able to search through a diary.
Even if I decide to paginate it eventually, it'll be easy, the backend will facilitate that.
The Details Matter
Since I provide my entire lifestream on one page, I also made sure to include the year for dates that precede this year. (Eg., October 5th, 2006. Note that that uses the intra-page anchor, another important detail.)
My lifestream has a discoverable RSS feed too.

But you know what? Nobody'd want a feed of a lifestream that constantly updates for individual entries. That's one thing that really bothers me about sweetcron feeds. They're just too noisy. Update, update, update!
So the RSS feed for my lifestream only provides weekly updates. That's what I'd really want from a lifestream feed. Just some sort of nice regular overview of all the activity over a certain period of time. And its permalinks are intra-page links into the huge complete history page.
Some of the accounts that I include in my lifestream don't support user activity feeds. For example, YouTube's feed for each user's Favorited videos doesn't have "date-favorited" information associated with it. Since I wrote my own lifestream engine, I was able to work around that problem. I doubt that most lifestream services like FriendFeed would go to the lengths I did in ensuring that I get exactly the information I want, regardless of whether or not the site's feed or API supports it.
It Helps Me Find Things
Searching for things half-remembered turns out to be pretty successful at the lifestream. I sometimes don't know if I posted a link to delicious, or if I plurked it.
It Encourages Me To Write More Clearly
I always think twice before I write a clever title to a tweet, plurk, or blog entry. I realize now that I may well be searching for that entry in the lifestream later, and the lifestream may only have the title. (The lifestream also contains actual content from the entries, but the content isn't presented in the web pages. So maybe the content will be searchable too, eventually.)
Cleverness is out. Accessibility and searchability are in when you have a persistant searchable lifestream. Now, I strive for clarity in my titles.
I also stopped services that cross-post from one service to another. Having the lifestream made the idea of cross-posting even more redundant. If my livejournal friends don't want to see my tweets, I won't force them to with LoudTwitter.
 Entries
Entries