
Dad's Project in the Garage

There's a trope about the dad who works constantly on his favorite old piece-of-junk project in the garage. He may never get it running, but getting it running is not the only point of the project. A bigger point is that it's the thing he goes to to clear his head and recharge. It's something that he can focus intently on, and it's something that's entirely in his domain.
I have a number of slow-burning projects at home, too. But they're not in the garage, they're in the cloud. Usually, they're web services. At work, as part of a team, I write code that goes on embedded devices. But at home, the entire product is mine. It's my chance to be a "full stack" engineer, the CEO, and principal customer all at once. It's nice to take on these different roles.
Updating a File
Let's take a quick look at updating a file. It's one of the most useful and common operations in programming, so it's really very well understood. A naive Python snippet to update a file with new data would look like the following:
with open(filename, 'wb') as f:
f.write(data)
What's beautiful about it is that it's cross-platform, and Python's "with" statement takes care of closing the file that was opened, even if an error occurs when writing the data.
But when you deploy code into the real world, you have to dive deeper, and think about what really can go wrong. For example, the automatic closing of the file I mentioned above? Python flushes data to the file, but doesn't necessarily sync the file to the physical disk. And in my case, it really does have to be cross platform, and I can only have one process access the file at a time, and I don't want IO errors corrupting the data. That means finding a cross-platform file lock, doing all the work on the side, and atomically moving the side file to the production file. The following snippet (elaborated a little more at this gist) fixes those problems.
with filelock.FileLock(filename):
with tempfile.NamedTemporaryFile(mode='wb',
dir=ntpath.dirname(filename),
delete=False) as f:
f.write(data)
f.flush()
if platform.system() == "Windows":
os.fsync(f.fileno()) # slower, but portable
if os.path.exists(filename):
os.unlink(filename) # or else WindowsError
else:
os.fdatasync(f.fileno()) # faster, Unix only
tempname = f.name
os.rename(tempname, filename) # Atomic on Unix
On the one hand, it's no longer a two-liner. On the other hand, I've got a function that works in all the environments I need it to, and I know exactly how it's going to behave in any exceptional situation.
Removing a Photo from a Web Album
My latest project is a web-based photo album. I could pay Flickr, Google or Apple for their web albums, of course, but they've made UX changes I don't like, and their costs are too high. So, I'm writing my own. It'll never be as polished as the production photo albums, but it'll be my jalopy, and I'll be able to tweak it in any way I choose.
One of the things my album owners need to do is delete photos they no longer want in the album. So, how should I implement that?
os.unlink(photo_filename)
That's the command to delete a file. You know it's not going to be that easy. Since we're talking about a web album, we'd want to consider a few things. We want an ideal user experience. It has to be fast, they have to be able to change their minds later, and concurrency can't be a problem. Here are some of the steps involved in deleting a photo from the album.
- Use JavaScript to make them confirm their choice in their Browser.
- Schedule the deletion of the entry in the local metadata file. It'll be done in a side thread or at a later time. Just make sure the user's web page's data refreshes quickly.
- Add a new entry to a list of timestamped-files-to-be-deleted-in-a-month.
- Run a cronjob that works on a regular cycle that actually does timestamp checking and the physical file deletion. (It's actually an S3 key deletion, which gets propagated to multiple cloud static-file servers behind the scenes. Even more remote complexity is encapsulated behind a single function call.)
What almost looked like it'd be a one-line call turns into JavaScript, AJAX, worker-thread creation, data file manipulation, and a cronjob with its own health and status reporting scheme.
This is fun! Amirite? This is what working on your own personal project is all about. So let's dive a little more deeply into step 2 above.
When the user confirms deletion of a photo, the first thing that should happen is that they get feedback. The photo needs to disappear from their view immediately. This happens before the server actually deletes the photo from persistent storage. JavaScript can manipulate the DOM right away in their browser. Over on the server, let's say you want to remove a photo's filename and its metadata from a list of photos.
Removing an Item from a Container
The task of removing the photo data from a list can be simplified to the task of removing a record from a container (l) when the first field of that record matches a certain criteria (s).
There's the loop:
for item in l:
if item[0] == s:
l.remove(item)
break
That's a straight forward imperative language neutral non-Pythonic implementation. Iterate across the container until you find the item, and then delete it right away. Unfortunately, l.remove(item) is another O(n) function being called inside an iteration of the list. That can be fixed with the enumerate call:
for idx,item in enumerate(l):
if item[0] == s:
del l[idx]
break
This is better. The enumerate() call returns an index that allows us to use the del call which takes only O(1) time.
Although that'd work, let's try to find a more modern and efficient solution. Use the enumerate call in a generator that returns the index of the item to be deleted:
idx = next((i for i,v in enumerate(l) if v[0] == s), None)
if idx is not None:
del l[idx]
The generator call is very efficient, and maybe we're done. No we're not! You see, it's a trick question. The actual answer is:
DELETE FROM l WHERE f = s LIMIT 1;
When it's your own project, you can change the domain! The data never had to be in a container that Python could process. Why not store it in a SQL database? Or, hey, just for grins, why not keep it in Python, but why was the container accessed like an unordered list? Was it ordered? Then do a binary search.
idx = bisect.bisect_left(l, [s, ])
if idx != len(l) and l[idx][0] == s:
del l[idx]
Nice, O(log n). Or, wait. Maybe it doesn't have to be ordered. Each photo has a unique filename. That's a key. Each photo's data could be a record in a Python set. Python has a "set" container that resembles mathematical sets with all the performance features you'd hope for. So let's make "l" be a set, and "r" be the row that has s in it, then...
l.remove(r)
Yay, that'll usually occur in constant order time! So have we found the best solution?
Of course not. We can make the theoretical problem as simple as we like. But in practice, the web album sometimes wants a database with different primary keys, sometimes it wants an ordered list of items, and sometimes it only needs a set of unique items.
For that matter, sometimes my user will be on a desktop computer, sometimes they'll be on a tablet, and often they'll be on their phone. That's a lot of CSS to experiment with.
That's what fiddling with your own personal project is all about! Dive deeply into whichever problem piques your interest at that moment. Make something work better. Even if the rest of the world doesn't know why you bother. Sometimes it's just what you need to be doing.
Photo by tashland / CC BY-NC-ND 2.0
Choosing a Cloud-based Backup Solution
Here's a comparison of some potential cloud backup solutions. I'd like to backup some desktop application settings to the cloud, user content from all the members of my family, and content from our mobile devices. It seems like every member of my family has different tastes in music, and we can't stop taking videos and photos.

Dropbox
Dropbox is a great tool, and it solves the problem of storing user content in the cloud. And it's free for the first 2 to 18 GB. (That's why the Dropbox line is blurry. The amount you get for free depends on what you do for them.) But it becomes $10.00 a month after that up to 100GB. and then more after that. And it doesn't backup certain non-Dropbox directories.
Microsoft SkyDrive offers a handy comparison of similar services, and it compares favorably in many cases. But all the services have similar drawbacks with regard to which media get backed up, and how media is shared or not shared across different accounts, each of which has to be paid for individually. By the way, you can check your current Google Drive storage here.
iCloud
For the members of the family that have iOS devices, we could backup to iCloud for free, up to 5GB. I really like that the backups would be effortless. But 5GB isn't very much for our photos, videos, and music nowadays. If we need more space, we could upgrade an iCloud or more, and our devices could share iClouds, but each cloud caps out at 55GB, and who would share which clouds? If our devices share clouds, would they have to sync the same media? That's not really what we want, and it doesn't help me out with my PC backup.
Dreamhost Backup
As a customer of Dreamhost, I get a free-for-the-first 50GB backup plan. That's quite decent. I'm using it already to backup my desktop. I love that the backup is done via rsync over ssh. It's flexible, smart, and encrypts my data on its way to the server in the cloud. But it's a single server in the cloud, and as such, it's a single point of failure. After the first 50GB, it's $0.10 per GB per month.
That's great for the desktop so far. But it doesn't help with the handheld devices unless I have them sync to the desktop, and then have the desktop sync to the cloud. That'd require user action, and that's a point of failure.
DreamObjects
Dreamhost offers high availability space (data is replicated three times, with immediate consistency) in the cloud for effective prices of under $0.07 per GB for developers. As an early adopter, I got in at a promotional rate. For the first 10 GB, DreamObjects isn't the cheapest solution, but after around 60 GB, then DreamObjects becomes a great solution based on price.
DreamObjects don't transfer via ssh, so if I want to encrypt my data, I have to do it myself. For data that doesn't need encryption, I can use boto-rsync which is like rsync. (Note that I linked to a fork that includes the "--exclude" argument.) For data that needs encryption, I'd do it with duplicity.
Of course, it's got the same problem as Dreamhost Backup. It doesn't help with the handheld devices unless I have them sync to the desktop, and then have the desktop sync to the cloud.
The Final Solution
You can't beat free. And you can't beat automatic. While simpler is better, and just choosing one solution would be the simplest, for a cheap developer like me, a hybrid solution looks the most attractive.
Everybody who's got iOS devices will backup the most important type of media that fits into 5 GB per iCloud. After that, we'll have to manually sync our handheld devices to a desktop, and that'll sync with DreamObjects. While I dislike that there'll be a manual step in getting some data into the cloud, I do like that this backup is device independent, and completely within my control.
Implementation Details
From a Linux box, or from an OSX command line, it's even easier than this. But if you're installing into CygWin, assuming you have easy_install installed, here are some installation notes for boto-rsync:
$ easy_install pip $ pip install boto_rsync
A boto-rsync command to DreamObjects looks like this:
$ boto-rsync -a "public_key" -s "secret_key" \ --endpoint objects.dreamhost.com \ --delete ~/dir-to-backup/ s3://bucket/dest-of-backup/
And for Duplicity, you'd need to have installed both librsync1 and librsync-devel from CygWin first. Then:
$ pip install httplib2 oauth $ curl -L http://goo.gl/VBVmB \ > duplicity-0.6.21.tar.gz $ tar xvzf duplicity-0.6.21.tar.gz $ cd duplicity-0.6.21/ $ python setup.py install
A duplicity command to DreamObjects looks like this, after you've configured a .boto file with your credentials:
$ env PASSPHRASE=yourpassphrase \ duplicity ~/dir-to-backup/ \ s3://objects.dreamhost.com/bucket/dest-of-backup
Edit: Here's a follow-up to this post written in 2016.
Finding an RSS Feed Reader to Replace Google Reader
As soon as the shuttering of Google Reader was announced, I went on the hunt for alternatives. I've researched various options, both self-hosted and cloud-based. I've tested them all in parallel for over a week, and have come to a tentative conclusion.
Your time is precious, here's my decision so far: My absolute favorite is selfoss. It's fast, minimal, and looks beautiful in both desktop and mobile formats. It happened to be very easy to install, and had no trouble taking in my OPML file, and it already had the right keyboard navigation keys configured. It mostly worked correctly right out of the box.
There were two settings I changed in the config.ini file:
homepage=unread auto_mark_as_read=1
That sets up the behavior I prefer. I want the site to always start with a list of unread content, and as I navigate around, I like the articles to be automatically marked as read.
Did it say it was minimal? Oh, it is. Gloriously so. And a bit too much. It makes for a very consistent reading experience because it strips away the effect of almost all HTML elements. No embedded videos, many pictures are not displayed, all text is displayed at one size and one weight.
That won't do for me. I want to see a little CSS beautification in my reader. Whitespace between paragraphs and seeing all the video and images is important to me. I need to know when the images are there. So I made some minor changes to the codebase.
- Removed elements like strong, b, em, i and p, from the strip-all-style part of public/all.css.
- I used this technique to remove elements from simplepie's strip_html list. I allowed iframe, object, param and embed in spouts/rss/feed.php for embedded videos.
- I turned off safe and whitelisted the embedded video tags in the htmLawed object in helpers/ContentLoader.php.
- Finally, I made this change from ref= to src= in helpers/ViewHelper.php.
Having made the changes above, now the feeds in my selfoss reader retain some rudimentary style and properly display video and images.
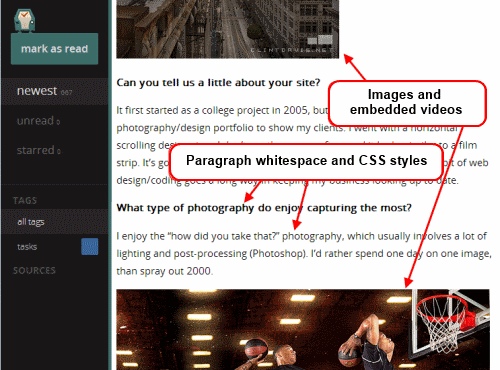
Now that's much better. This is a selfoss installation that I can live with.
As for the runner-ups? I liked Tiny Tiny RSS a lot. But it was slower loading and responding. And the visual presentation for desktop mode wasn't as nice. There's too much clutter. Its mobile version is not supported, but ttrss-mobile is awesome. Install it into /mobile for the easiest experience. Finally, remap they keys j and k to next_article_noscroll and prev_article_noscroll with a plugin.
If I were forced to go with a 3rd party cloud-based product, I'd probably choose Feedly. It's relatively fast and minimal. After that, it's a toss-up between NetVibes and The Old Reader. I didn't pay NewsBlur to see how they'd perform with a moderately large OPML. I'm looking forward to seeing what Digg comes up with.
And as for local desktop clients? They're not in the running. I need my feedreader to be current on any screen I happen to login to.
Finally, some suggest using Twitter as Google Reader's replacement. I enjoy "dipping into the stream" as it were in Twitter, Facebook and Reddit. But I need a tool that'll save articles from my favorite friends and content creators too.
I hope you may find this helpful. If nothing else, it'll serve to pinpoint the state of the art in early 2013 for keeping track of content online.
Happy Birthday, Me. I got you Vim!
I used to play NetHack. The keyboard keys it uses to navigate your player are the same screen navigation keys for the editor vi. So I've always been able to make do with vi and its successor, Vim.
I've recently decided to give Vim a serious look, since it's still ubiquitous after more than 20 years, (I find myself having to ssh to remote computers more often then I expected), and I have really smart, productive colleagues who use it everyday. Somehow, it has stood the test of time. Vim is one of those tools that increases in value exponentially if you invest the time to become proficient in it.
So, in the grand tradition of giving myself strange intangible gifts like giving myself data portability a couple of years ago, this year, I decided to invest some time in Vim.
I'm still new to it, but I've tasted the change in mindset that happens as you get better and better at Vim. It feels like you're programming the act of text editing, and I mean that in the best way possible. (This is coming from a guy who spends his free time programming cron jobs.)
Time for a screen shot of what Vim looks like for me when I'm working on a shell command. Click on it to see it at full size.
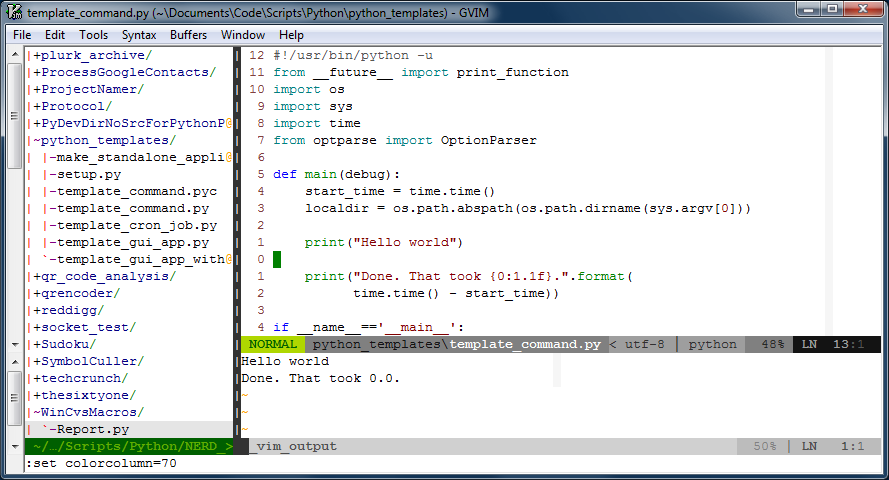
There are three "windows" in the image above. The window on the left is a tree-view of the files on disk. That window is managed by a script called, NERDTree, and it's usually closed. I only open that when I need to look at another file. On the right are two windows, one above the other. The larger one is on top, and is the "main" window that hosts the main buffer that I'm actively editing. The smaller window on the bottom is an "output" window, that prints out the results of the script I'm editing whenever I run it.
That image represents an iterative workflow where I edit (possibly multiple buffers) in the biggest window, hit <F5> to run the script, and see the output displayed in the window below. It's a workflow that works well for small scripts.
There are a few things about that window that I'd like to point out:
One:The line numbers are relative to the current position of the cursor. This is really handy because Vim's normal mode commands work nicely with line number counts. The line numbers change automatically to absolute line numbers when the window loses focus. That's accomplished by this bit in my .vimrc file:
autocmd FocusLost * if &relativenumber | set number | endif autocmd FocusGained * if &number | set relativenumber | endif
Here's a great explanation for why to switch between relative and absolute line numbers in vim.
Two: There's a very subtle light gray column at column 70 in the image. Usually it's at column 80, but I bumped it in to take the screenshot. That column helps remind me to keep my code lines short.
Three: There are a few plugins doing work behind the scenes. You can see one called powerline just under the main window. Powerline is a very handy status line. What you can't see in the image are other plugins like taglist that help when one is developing code. Vim also support syntax completion.
Four: Vim is very customizable, and it sometimes needs it. For example, I like the behavior from setting smartindent, except when it un-indents the # character to the first column of the line. In Python, the # character starts a comment, and I want it to remain in the column in which I put it. Here's what I've added to my .vimrc file to fix that issue:
set smartindent autocmd FileType python inoremap # X<c-h>#
Boo that Vim doesn't always do what you want out of the box. Yay that it always can be fixed to work the way you'd prefer.
Five: Vim lets you continue to undo actions from your previous sessions with the file, if you like. Isn't that an awesome option to have? If you want it, the option to set is:
set undofile
Far better than what I've written here, I strongly recommend Steve Losh's article, Coming Home to Vim. He's got a lot more experience with Vim, and he makes a compelling case for it.
It's a work-in-progress, but I'm willing to share what I've got so far in my .vimrc file. You'll see that I customize far more than I mention here in this article. Once it's stable, I may maintain it in a repository at github.
The Well-Mannered Daemon

The subject line is a bit of a lie. It's not a well-mannered daemon so much as it is a well-mannered cronjob. But it's more fun to say daemon.
I had to make a new cronjob. As is occasionally the way with things, NetFlix saw fit to remove their AtHomeRSS feeds. I used that feed at my lifestream, so I needed a replacement.
I rebuilt the AtHomeRSS feed, and I made the complete source code available. Disclaimer, it's code that was written between 11:00pm and 2:00am over a couple of nights. You get what you paid for.
The point of the repository over there at GitHub is the new script that makes an RSS feed by scraping email. But still, I thought it was interesting how much code was dedicated to making the cronjob be well-mannered. I expect my daemons and cronjobs to have the following attributes:
Accountable
Do the job quietly, and write a short status report on how it went. No need to interrupt me if things went fine. But I do want to be able to check-in on it, and know if anything interesting happened. My cronjob writes a line (or more) to a status file every time it checks the email. It also trims away really old entries from the file, keeping it short.
Diligent
If it does encounter a problem, I want it to let me know right away. That's not something to just put in the status report. It should ask for help and email me with any problems that it doesn't know how to handle itself.
Adaptable
When I need to give the cronjob new instructions, it should be easy. It shouldn't fastidiously insist on writing reports or sending me emails as I'm in the process of giving it new directives. This cronjob allows me to quickly test changes with a --debug flag.
Dependable
This last trait is mostly just thrown in there. It automatically applies to all software, since you only have to write it once, and all things working correctly, it'll do what you tell it to. Still, that's what's beautiful about software. Any time I find myself repeating a task, I find myself wondering, could I just automate this?
There's an interesting description that accompanies the photo that I used as the header for this image. The photo is of "Machine with Concrete." Ars Electronica writes, "Arthur Ganson (US) reminds those partaking of it that the human being is the only creature on Earth to build machines that (are meant to) outlive their creator." My daemons and cronjobs are meant to outlive me.
Photo by Ars Electronica / CC BY-NC-ND 2.0
 Entries
Entries